Resource Embedding
PostgREST allows including related resources in a single API call. This reduces the need for many API requests.
Foreign Key Joins
The server uses Foreign Keys to determine which database objects can be joined together. It supports joining tables, views and table-valued functions.
For tables, it generates a join condition using the foreign keys columns (respecting composite keys).
For views, it generates a join condition using the views’ base tables foreign key columns.
For table-valued functions, it generates a join condition based on the foreign key columns of the returned table type.
Important
Whenever foreign keys change you must do Schema Cache Reloading for this feature to work.
Relationships
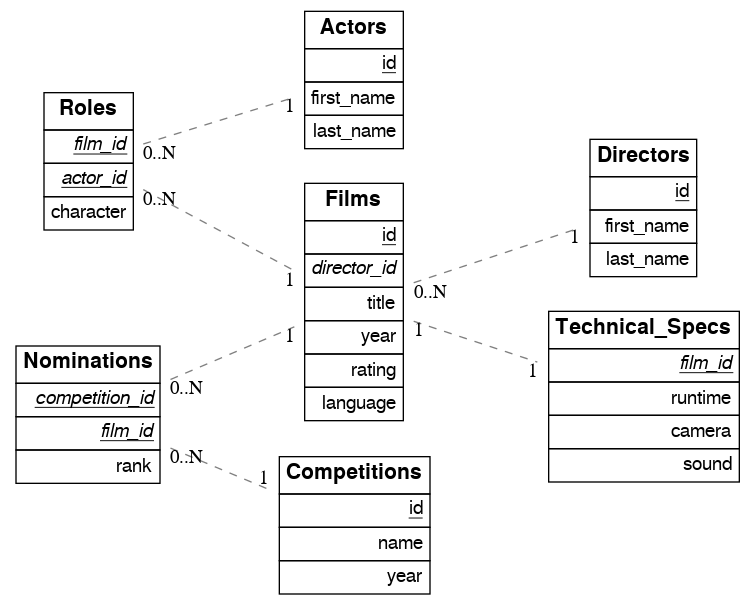
For example, consider a database of films and their awards:
create table actors(
id int primary key generated always as identity,
first_name text,
last_name text
);
create table directors(
id int primary key generated always as identity,
first_name text,
last_name text
);
create table films(
id int primary key generated always as identity,
director_id int references directors(id),
title text,
year int,
rating numeric(3,1),
language text
);
create table technical_specs(
film_id int references films(id) primary key,
runtime time,
camera text,
sound text
);
create table roles(
film_id int references films(id),
actor_id int references actors(id),
character text,
primary key(film_id, actor_id)
);
create table competitions(
id int primary key generated always as identity,
name text,
year int
);
create table nominations(
competition_id int references competitions(id),
film_id int references films(id),
rank int,
primary key (competition_id, film_id)
);
Many-to-one relationships
Since films has a foreign key to directors, this establishes a many-to-one relationship. This enables us to request all the films and the director for each film.
curl "http://localhost:3000/films?select=title,directors(id,last_name)"
[
{ "title": "Workers Leaving The Lumière Factory In Lyon",
"directors": {
"id": 2,
"last_name": "Lumière"
}
},
{ "title": "The Dickson Experimental Sound Film",
"directors": {
"id": 1,
"last_name": "Dickson"
}
},
{ "title": "The Haunted Castle",
"directors": {
"id": 3,
"last_name": "Méliès"
}
}
]
Note that the embedded directors is returned as a JSON object because of the “to-one” end.
Since the table name is plural, we can be more accurate by making it singular with an alias.
curl "http://localhost:3000/films?select=title,director:directors(id,last_name)"
[
{ "title": "Workers Leaving The Lumière Factory In Lyon",
"director": {
"id": 2,
"last_name": "Lumière"
}
},
".."
]
One-to-many relationships
The foreign key reference establishes the inverse one-to-many relationship. In this case, films returns as a JSON array because of the “to-many” end.
curl "http://localhost:3000/directors?select=last_name,films(title)"
[
{ "last_name": "Lumière",
"films": [
{"title": "Workers Leaving The Lumière Factory In Lyon"}
]
},
{ "last_name": "Dickson",
"films": [
{"title": "The Dickson Experimental Sound Film"}
]
},
{ "last_name": "Méliès",
"films": [
{"title": "The Haunted Castle"}
]
}
]
Many-to-many relationships
The join table determines many-to-many relationships. It must contain foreign keys to other two tables and they must be part of its composite key. In the sample film database, roles is taken as a join table.
The join table is also detected if the composite key has additional columns.
create table roles(
id int generated always as identity,
, film_id int references films(id)
, actor_id int references actors(id)
, character text,
, primary key(id, film_id, actor_id)
);
curl "http://localhost:3000/actors?select=first_name,last_name,films(title)"
[
{ "first_name": "Willem",
"last_name": "Dafoe",
"films": [
{"title": "The Lighthouse"}
]
},
".."
]
One-to-one relationships
One-to-one relationships are detected in two ways. (We’ll use the films and technical_specs tables from the sample film database as an example).
When the foreign key is also a primary key.
create table technical_specs( film_id int references films(id) primary key -- ... );
Or when the foreign key has a unique constraint.
create table technical_specs( id int primary key , film_id int references films(id) unique -- ... );
curl "http://localhost:3000/films?select=title,technical_specs(camera)"
[
{
"title": "Pulp Fiction",
"technical_specs": {"camera": "Arriflex 35-III"}
},
".."
]
Computed Relationships
You can manually define relationships by using functions. This is useful for database objects that can’t define foreign keys, like Foreign Data Wrappers.
Computed relationships have good performance as their intended design enable function inlining.
Important
Always use
SETOFwhen creating computed relationships. Functions can return a table without usingSETOF, but bear in mind that PostgreSQL will not inline them. e.g.RETURNS <table_name>is not inlinable.
Assuming there’s a foreign table premieres that we want to relate to films.
create foreign table premieres (
id integer,
location text,
"date" date,
film_id integer
) server import_csv options ( filename '/tmp/directors.csv', format 'csv');
create function film(premieres) returns setof films rows 1 as $$
select * from films where id = $1.film_id
$$ stable language sql;
The above function defines a relationship between premieres (the parameter) and films (the return type). Since there’s a rows 1, this defines a many-to-one relationship.
The name of the function film is arbitrary and can be used to do the embedding:
curl "http://localhost:3000/premieres?select=location,film(name)"
[
{
"location": "Cannes Film Festival",
"film": {"name": "Pulp Fiction"}
},
".."
]
Warning
Make sure to correctly label the
to-onepart of the relationship. When using theROWS 1estimation, PostgREST will expect a single row to be returned. If that is not the case, it will unnest the embedding and return repeated values for the top level resource.
Now let’s define the opposite one-to-many relationship.
create function premieres(films) returns setof premieres as $$
select * from premieres where film_id = $1.id
$$ stable language sql;
In this case there’s an implicit ROWS 1000 defined by PostgreSQL(search “result_rows” on this PostgreSQL doc).
We consider any value greater than 1 as “many” so this defines a one-to-many relationship.
curl "http://localhost:3000/films?select=name,premieres(name)"
[
{
"name": "Pulp Ficiton",
"premieres": [{"location": "Cannes Festival"}]
},
".."
]
Overriding Relationships
Computed relationships also allow you to override the ones that PostgREST auto-detects.
For example, to override the many-to-one relationship between films and directors.
create function directors(films) returns setof directors rows 1 as $$
select * from directors where id = $1.director_id
$$ stable language sql;
Thanks to overloaded functions, you can use the same function name for different parameters. Thus define relationships from other tables/views to directors.
create function directors(film_schools) returns setof directors as $$
select * from directors where film_school_id = $1.id
$$ stable language sql;
Computed relationships have good performance as their intended design enable function inlining.
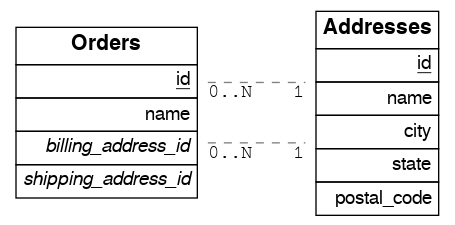
Foreign Key Joins on Multiple Foreign Key Relationships
When there are multiple foreign keys between tables, Foreign Key Joins need disambiguation to resolve which foreign key columns to use for the join.
To do this, you can specify a foreign key by using the !<fk> syntax.
Multiple Many-To-One
For example, suppose you have the following orders and addresses tables:
create table addresses (
id int primary key generated always as identity,
name text,
city text,
state text,
postal_code char(5)
);
create table orders (
id int primary key generated always as identity,
name text,
billing_address_id int,
shipping_address_id int,
constraint billing foreign key(billing_address_id) references addresses(id),
constraint shipping foreign key(shipping_address_id) references addresses(id)
);
Since the orders table has two foreign keys to the addresses table, a foreign key join is ambiguous and PostgREST will respond with an error:
curl "http://localhost:3000/orders?select=*,addresses(*)" -i
HTTP/1.1 300 Multiple Choices
{
"code": "PGRST201",
"details": [
{
"cardinality": "many-to-one",
"embedding": "orders with addresses",
"relationship": "billing using orders(billing_address_id) and addresses(id)"
},
{
"cardinality": "many-to-one",
"embedding": "orders with addresses",
"relationship": "shipping using orders(shipping_address_id) and addresses(id)"
}
],
"hint": "Try changing 'addresses' to one of the following: 'addresses!billing', 'addresses!shipping'. Find the desired relationship in the 'details' key.",
"message": "Could not embed because more than one relationship was found for 'orders' and 'addresses'"
}
To successfully join orders with addresses, we can follow the error hint which tells us to add the foreign key name as !billing or !shipping.
Note that the foreign keys have been named explicitly in the SQL definition above. To make the result clearer we’ll also alias the tables:
# curl "http://localhost:3000/orders?select=name,billing_address:addresses!billing(name),shipping_address:addresses!shipping(name)"
curl --get "http://localhost:3000/orders" \
-d "select=name,billing_address:addresses!billing(name),shipping_address:addresses!shipping(name)"
[
{
"name": "Personal Water Filter",
"billing_address": {
"name": "32 Glenlake Dr.Dearborn, MI 48124"
},
"shipping_address": {
"name": "30 Glenlake Dr.Dearborn, MI 48124"
}
}
]
Multiple One-To-Many
Let’s take the tables from Multiple Many-To-One. To get the opposite one-to-many relationship, we can also specify the foreign key name:
# curl "http://localhost:3000/addresses?select=name,billing_orders:orders!billing(name),shipping_orders!shipping(name)&id=eq.1"
curl --get "http://localhost:3000/addresses" \
-d "select=name,billing_orders:orders!billing(name),shipping_orders!shipping(name)" \
-d "id=eq.1"
[
{
"name": "32 Glenlake Dr.Dearborn, MI 48124",
"billing_orders": [
{ "name": "Personal Water Filter" },
{ "name": "Coffee Machine" }
],
"shipping_orders": [
{ "name": "Coffee Machine" }
]
}
]
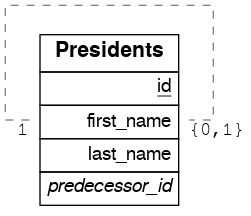
Recursive Relationships
To disambiguate recursive relationships, PostgREST requires Computed Relationships.
Recursive One-To-One
create table presidents (
id int primary key generated always as identity,
first_name text,
last_name text,
predecessor_id int references presidents(id) unique
);
To get either side of the Recursive One-To-One relationship, create the functions:
create or replace function predecessor(presidents) returns setof presidents rows 1 as $$
select * from presidents where id = $1.predecessor_id
$$ stable language sql;
create or replace function successor(presidents) returns setof presidents rows 1 as $$
select * from presidents where predecessor_id = $1.id
$$ stable language sql;
Now, to query a president with their predecessor and successor:
# curl "http://localhost:3000/presidents?select=last_name,predecessor(last_name),successor(last_name)&id=eq.2"
curl --get "http://localhost:3000/presidents" \
-d "select=last_name,predecessor(last_name),successor(last_name)" \
-d "id=eq.2"
[
{
"last_name": "Adams",
"predecessor": {
"last_name": "Washington"
},
"successor": {
"last_name": "Jefferson"
}
}
]
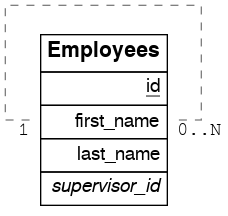
Recursive One-To-Many
create table employees (
id int primary key generated always as identity,
first_name text,
last_name text,
supervisor_id int references employees(id)
);
To get the One-To-Many embedding, that is, the supervisors with their supervisees, create a function like this one:
create or replace function supervisees(employees) returns setof employees as $$
select * from employees where supervisor_id = $1.id
$$ stable language sql;
Now, the query would be:
# curl "http://localhost:3000/employees?select=last_name,supervisees(last_name)&id=eq.1"
curl --get "http://localhost:3000/employees" \
-d "select=last_name,supervisees(last_name)" \
-d "id=eq.1"
[
{
"name": "Taylor",
"supervisees": [
{ "name": "Johnson" },
{ "name": "Miller" }
]
}
]
Recursive Many-To-One
Let’s take the same employees table from Recursive One-To-Many.
To get the Many-To-One relationship, that is, the employees with their respective supervisor, you need to create a function like this one:
create or replace function supervisor(employees) returns setof employees rows 1 as $$
select * from employees where id = $1.supervisor_id
$$ stable language sql;
Then, the query would be:
# curl "http://localhost:3000/employees?select=last_name,supervisor(last_name)&id=eq.3"
curl --get "http://localhost:3000/employees" \
-d "select=last_name,supervisor(last_name)" \
-d "id=eq.3"
[
{
"last_name": "Miller",
"supervisor": {
"last_name": "Taylor"
}
}
]
Recursive Many-To-Many
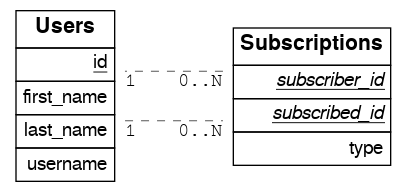
create table users (
id int primary key generated always as identity,
first_name text,
last_name text,
username text unique
);
create table subscriptions (
subscriber_id int references users(id),
subscribed_id int references users(id),
type text,
primary key (subscriber_id, subscribed_id)
);
To get all the subscribers of a user as well as the ones they’re following, define these functions:
create or replace function subscribers(users) returns setof users as $$
select u.*
from users u,
subscriptions s
where s.subscriber_id = u.id and
s.subscribed_id = $1.id
$$ stable language sql;
create or replace function following(users) returns setof users as $$
select u.*
from users u,
subscriptions s
where s.subscribed_id = u.id and
s.subscriber_id = $1.id
$$ stable language sql;
Then, the request would be:
# curl "http://localhost:3000/users?select=username,subscribers(username),following(username)&id=eq.4"
curl --get "http://localhost:3000/users" \
-d "select=username,subscribers(username),following(username)" \
-d "id=eq.4"
[
{
"username": "the_top_artist",
"subscribers": [
{ "username": "patrick109" },
{ "username": "alicia_smith" }
],
"following": [
{ "username": "top_streamer" }
]
}
]
Foreign Key Joins on Partitioned Tables
Foreign Key joins can also be done between partitioned tables and other tables.
For example, let’s create the box_office partitioned table that has the gross daily revenue of a film:
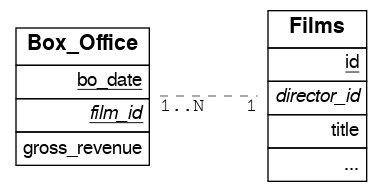
CREATE TABLE box_office (
bo_date DATE NOT NULL,
film_id INT REFERENCES films NOT NULL,
gross_revenue DECIMAL(12,2) NOT NULL,
PRIMARY KEY (bo_date, film_id)
) PARTITION BY RANGE (bo_date);
-- Let's also create partitions for each month of 2021
CREATE TABLE box_office_2021_01 PARTITION OF box_office
FOR VALUES FROM ('2021-01-01') TO ('2021-01-31');
CREATE TABLE box_office_2021_02 PARTITION OF box_office
FOR VALUES FROM ('2021-02-01') TO ('2021-02-28');
-- and so until december 2021
Since it contains the films_id foreign key, it is possible to join box_office and films:
# curl "http://localhost:3000/box_office?select=bo_date,gross_revenue,films(title)&gross_revenue=gte.1000000"
curl --get "http://localhost:3000/box_office" \
-d "select=bo_date,gross_revenue,films(title)" \
-d "gross_revenue=gte.1000000"
Note
Foreign key joins on partitions is not allowed because it leads to ambiguity errors (see Foreign Key Joins on Multiple Foreign Key Relationships) between them and their parent partitioned table. More details at #1783(comment)). Computed Relationships can be used if this is needed.
Partitioned tables can reference other tables since PostgreSQL 11 but can only be referenced from any other table since PostgreSQL 12.
Foreign Key Joins on Views
PostgREST will infer the foreign keys of a view using its base tables. Base tables are the ones referenced in the FROM and JOIN clauses of the view definition.
The foreign keys’ columns must be present in the top SELECT clause of the view for this to work.
For instance, the following view has nominations, films and competitions as base tables:
CREATE VIEW nominations_view AS
SELECT
films.title as film_title
, competitions.name as competition_name
, nominations.rank
, nominations.film_id as nominations_film_id
, films.id as film_id
FROM nominations
JOIN films ON films.id = nominations.film_id
JOIN competitions ON competitions.id = nominations.competition_id;
Since this view contains nominations.film_id, which has a foreign key relationship to films, then we can join the films table. Similarly, because the view contains films.id, then we can also join the roles and the actors tables (the last one in a many-to-many relationship):
# curl "http://localhost:3000/nominations_view?select=film_title,films(language),roles(character),actors(last_name,first_name)&rank=eq.5"
curl --get "http://localhost:3000/nominations_view" \
-d "select=film_title,films(language),roles(character),actors(last_name,first_name)" \
-d "rank=eq.5"
It’s also possible to foreign key join Materialized Views.
Important
It’s not guaranteed that foreign key joins will work on all kinds of views. In particular, foreign key joins won’t work on views that contain UNIONs.
Why? PostgREST detects base table foreign keys in the view by querying and parsing pg_rewrite. This may fail depending on the complexity of the view.
As a workaround, you can use Computed Relationships to define manual relationships for views.
If view definitions change you must refresh PostgREST’s schema cache for this to work properly. See the section Schema Cache Reloading.
Foreign Key Joins on Chains of Views
Views can also depend on other views, which in turn depend on the actual base table. For PostgREST to pick up those chains recursively to any depth, all the views must be in the search path, so either in the exposed schema (db-schemas) or in one of the schemas set in db-extra-search-path. This does not apply to the base table, which could be in a private schema as well. See Schema Isolation for more details.
Foreign Key Joins on Table-Valued Functions
If you have a Function that returns a table type, you can do a Foreign Key join on the result.
Here’s a sample function (notice the RETURNS SETOF films).
CREATE FUNCTION getallfilms() RETURNS SETOF films AS $$
SELECT * FROM films;
$$ LANGUAGE SQL STABLE;
A request with directors embedded:
# curl "http://localhost:3000/rpc/getallfilms?select=title,directors(id,last_name)&title=like.*Workers*"
curl --get "http://localhost:3000/rpc/getallfilms" \
-d "select=title,directors(id,last_name)" \
-d "title=like.*Workers*"
[
{ "title": "Workers Leaving The Lumière Factory In Lyon",
"directors": {
"id": 2,
"last_name": "Lumière"
}
}
]
Foreign Key Joins on Writes
You can join related database objects after doing Insert, Update or Delete.
Say you want to insert a film and then get some of its attributes plus join its director.
curl "http://localhost:3000/films?select=title,year,director:directors(first_name,last_name)" \
-H "Prefer: return=representation" \
-d @- << EOF
{
"id": 100,
"director_id": 40,
"title": "127 hours",
"year": 2010,
"rating": 7.6,
"language": "english"
}
EOF
Response:
{
"title": "127 hours",
"year": 2010,
"director": {
"first_name": "Danny",
"last_name": "Boyle"
}
}
Nested Embedding
If you want to embed through join tables but need more control on the intermediate resources, you can do nested embedding. For instance, you can request the Actors, their Roles and the Films for those Roles:
curl "http://localhost:3000/actors?select=roles(character,films(title,year))"
Embedded Filters
Embedded resources can be shaped similarly to their top-level counterparts. To do so, prefix the query parameters with the name of the embedded resource. For instance, to order the actors in each film:
# curl "http://localhost:3000/films?select=*,actors(*)&actors.order=last_name,first_name"
curl --get "http://localhost:3000/films" \
-d "select=*,actors(*)" \
-d "actors.order=last_name,first_name"
This sorts the list of actors in each film but does not change the order of the films themselves. To filter the roles returned with each film:
# curl "http://localhost:3000/films?select=*,roles(*)&roles.character=in.(Chico,Harpo,Groucho)"
curl --get "http://localhost:3000/films" \
-d "select=*,roles(*)" \
-d "roles.character=in.(Chico,Harpo,Groucho)"
Once again, this restricts the roles included to certain characters but does not filter the films in any way. Films without any of those characters would be included along with empty character lists.
An or filter can be used for a similar operation:
# curl "http://localhost:3000/films?select=*,roles(*)&roles.or=(character.eq.Gummo,character.eq.Zeppo)"
curl --get "http://localhost:3000/films" \
-d "select=*,roles(*)" \
-d "roles.or=(character.eq.Gummo,character.eq.Zeppo)"
However, this only works for columns inside roles. See how to use “or” across multiple resources.
Limit and offset operations are possible:
# curl "http://localhost:3000/films?select=*,actors(*)&actors.limit=10&actors.offset=2"
curl --get "http://localhost:3000/films" \
-d "select=*,actors(*)" \
-d "actors.limit=10" \
-d "actors.offset=2"
Embedded resources can be aliased and filters can be applied on these aliases:
# curl "http://localhost:3000/films?select=*,actors(*)&actors.limit=10&actors.offset=2"
curl --get "http://localhost:3000/films" \
-d "select=*,90_comps:competitions(name),91_comps:competitions(name)" \
-d "90_comps.year=eq.1990" \
-d "91_comps.year=eq.1991"
Filters can also be applied on nested embedded resources:
# curl "http://localhost:3000/films?select=*,roles(*,actors(*))&roles.actors.order=last_name&roles.actors.first_name=like.*Tom*"
curl --get "http://localhost:3000/films" \
-d "select=*,roles(*,actors(*))" \
-d "roles.actors.order=last_name" \
-d "roles.actors.first_name=like.*Tom*"
The result will show the nested actors named Tom and order them by last name. Aliases can also be used instead of the resource names to filter the nested tables.
Top-level Filtering
By default, Embedded Filters don’t change the top-level resource(films) rows at all:
# curl "http://localhost:3000/films?select=title,actors(first_name,last_name)&actors.first_name=eq.Jehanne
curl --get "http://localhost:3000/films" \
-d "select=title,actors(first_name,last_name)" \
-d "actors.first_name=eq.Jehanne"
[
{
"title": "Workers Leaving The Lumière Factory In Lyon",
"actors": []
},
{
"title": "The Dickson Experimental Sound Film",
"actors": []
},
{
"title": "The Haunted Castle",
"actors": [
{
"first_name": "Jehanne",
"last_name": "d'Alcy"
}
]
}
]
In order to filter the top level rows you need to add !inner to the embedded resource. For instance, to get only the films that have an actor named Jehanne:
# curl "http://localhost:3000/films?select=title,actors!inner(first_name,last_name)&actors.first_name=eq.Jehanne"
curl --get "http://localhost:3000/films" \
-d "select=title,actors!inner(first_name,last_name)" \
-d "actors.first_name=eq.Jehanne"
[
{
"title": "The Haunted Castle",
"actors": [
{
"first_name": "Jehanne",
"last_name": "d'Alcy"
}
]
}
]
Null filtering on Embedded Resources
Null filtering on the embedded resources can behave the same as !inner. While providing more flexibility.
For example, doing actors=not.is.null returns the same result as actors!inner(*):
# curl "http://localhost:3000/films?select=title,actors(*)&actors=not.is.null"
curl --get "http://localhost:3000/films" \
-d "select=title,actors(*)" \
-d "actors=not.is.null"
The is.null filter can be used in embedded resources to perform an anti-join. To get all the films that do not have any nominations:
# curl "http://localhost:3000/films?select=title,nominations()&nominations=is.null"
curl --get "http://localhost:3000/films" \
-d "select=title,nominations()" \
-d "nominations=is.null"
Both is.null and not.is.null can be included inside the or operator. For instance, to get the films that have no actors or directors registered yet:
# curl "http://localhost:3000/films?select=title,nominations()&nominations=is.null"
curl --get "http://localhost:3000/films" \
-d select=title,actors(*),directors(*)" \
-d "or=(actors.is.null,directors.is.null)"
OR filtering across Embedded Resources
You can also use not.is.null to make an or filter across multiple resources.
For instance, to show the films with actors or directors named John:
# curl "http://localhost:3000/films?select=title,actors(),directors()&directors.first_name=eq.John&actors.first_name=eq.John&or=(directors.not.is.null,actors.not.is.null)"
curl --get "http://localhost:3000/films" \
-d "select=title,actors(),directors()" \
-d "directors.first_name=eq.John" \
-d "actors.first_name=eq.John" \
-d "or=(directors.not.is.null,actors.not.is.null)"
[
{ "title": "Pulp Fiction" },
{ "title": "The Thing" },
".."
]
Here, we use empty embeds because retrieving their info would be restricted by the filters.
For example, the directors embedding would return null if its first_name is not John.
To solve this, you need to add extra embedded resources and use the empty ones for filtering.
From the above example:
# curl "http://localhost:3000/films?select=title,act:actors(),dir:directors(),actors(first_name),directors(first_name)&dir.first_name=eq.John&act.first_name=eq.John&or=(dir.not.is.null,act.not.is.null)"
curl --get "http://localhost:3000/films" \
# We need to use aliases like "act" and "dir" to filter the empty embeds
-d "select=title,act:actors(),dir:directors(),actors(first_name),directors(first_name)" \
-d "dir.first_name=eq.John" \
-d "act.first_name=eq.John" \
-d "or=(dir.not.is.null,act.not.is.null)"
[
{
"title": "Pulp Fiction",
"actors": [
{ "first_name": "John" },
{ "first_name": "Samuel" },
{ "first_name": "Uma" },
".."
]
"directors": {
"first_name": "Quentin"
}
},
".."
]
Empty Embed
You can leave an embedded resource empty, this helps with filtering in some cases.
To filter the films by actors but not include them:
# curl "http://localhost:3000/films?select=title,actors()&actors.first_name=eq.Jehanne&actors=not.is.null"
curl --get "http://localhost:3000/films" \
-d "select=title,actors()" \
-d "actors.first_name=eq.Jehanne" \
-d "actors=not.is.null"
[
{
"title": "The Haunted Castle",
}
]
Top-level Ordering
On Many-to-One and One-to-One relationships, you can use a column of the “to-one” end to sort the top-level.
For example, to arrange the films in descending order using the director’s last name.
# curl "http://localhost:3000/films?select=title,directors(last_name)&order=directors(last_name).desc"
curl --get "http://localhost:3000/films" \
-d "select=title,directors(last_name)" \
-d "order=directors(last_name).desc"
Spread embedded resource
You can modify the shape of the embedded resources by using the spread syntax (...).
Spread To-One relationships
Spread on resources forming one-to-one and many-to-one relationships, will lift the embedded columns to the top object.
curl --get "http://localhost:3000/films" \
-d "select=title,...directors(director_first_name:first_name, director_last_name:last_name)" \
-d "title=like.*Workers*"
[
{
"title": "Workers Leaving The Lumière Factory In Lyon",
"director_first_name": "Louis",
"director_last_name": "Lumière"
}
]
Note that there is no wrapping "directors" object, unlike regularly embedding many-to-one relationships. Also note that embedded columns can be aliased normally.
Spread To-Many relationships
Spread on resources forming one-to-many and many-to-many relationships, will convert the embedded columns into correlated arrays.
curl --get "http://localhost:3000/directors" \
-d "select=first_name,...films(film_titles:title,film_years:year)" \
-d "first_name=like.Quentin*"
[
{
"first_name": "Quentin",
"film_titles": [
"Pulp Fiction",
"Reservoir Dogs"
],
"film_years": [
1994,
1992
]
}
]
Note that films is no longer an array of objects, unlike regularly embedding One-to-many relationships. The embedded columns become arrays and they’re correlated-in the above result, we can say that “Pulp Fiction” premiered in 1994 and “Reservoir Dogs” in 1992.
Order in spread to-many
In the above example, the order of the values inside the correlated arrays is unspecified, but all the values are guaranteed to be in the same unspecified order.
You can order the correlated arrays explicitly. For example, to order by the film year:
curl --get "http://localhost:3000/directors" \
-d "select=first_name,...films(film_titles:title,film_years:year)" \
-d "first_name=like.Quentin*" \
-d "films.order=year"
[
{
"first_name": "Quentin",
"film_titles": [
"Reservoir Dogs",
"Pulp Fiction"
],
"film_years": [
1992,
1994
]
}
]
Warning
Aliasing spread columns is recommended since JSON allows duplicate keys. Example:
curl --get "localhost:3000/projects" \
-d "select=id,name,...clients(id,name)"
[{"id":1,"name":"Windows 7","id":1,"name":"Microsoft"},
{"id":2,"name":"Windows 10","id":1,"name":"Microsoft"},
{"id":3,"name":"IOS","id":2,"name":"Apple"},
{"id":4,"name":"OSX","id":2,"name":"Apple"},
{"id":5,"name":"Orphan","id":null,"name":null}]
This can be a problem in Javascript objects, since only the last duplicated key will be considered. To solve it do:
curl --get "localhost:3000/projects" \
-d "select=id,name,...clients(client_id:id,client_name:name)"
Multiple Spreads
You can use multiple spreads at any level. For example, let’s spread technical_specs and roles into films and then spread films into directors:
curl --get "http://localhost:3000/directors" \
-d "select=first_name,...films(film_titles:title,film_years:year,...technical_specs(film_runtimes:runtime),...roles(film_characters:character))" \
-d "first_name=like.Quentin*" \
-d "films.order=year" \
-d "films.roles.order=character"
[
{
"first_name": "Quentin",
"film_titles": [
"Reservoir Dogs",
"Pulp Fiction"
],
"film_years": [
1992,
1994
],
"film_runtimes": [
"01:39:00",
"02:29:00"
]
"film_characters": [
[ "Mr. Pink", "Mr. White" ],
[ "Mia Wallace", "Vincent Vega" ]
]
}
]
Note that:
All the
film_*arrays are correlated-“Reservoir Dogs” premiered in 1992, its runtime is 1:39:00 and it has the following characters:[ "Mr. Pink", "Mr. White" ].The
film_*arrays are ordered byyear(due tofilms.order=year).The bottom level array
film_charactersis ordered (due tofilms.roles.order=character).
Spread a join table
Spread can be used to move the columns of a join table in a many-to-many to the top object. For instance, to get the character column of the roles join table into actors:
curl --get "http://localhost:3000/films" \
-d "select=title,actors:roles(character,...actors(first_name,last_name))" \
-d "title=like.*Lighthouse*"
[
{
"title": "The Lighthouse",
"actors": [
{
"character": "Thomas Wake",
"first_name": "Willem",
"last_name": "Dafoe"
}
]
}
]