Tables and Views
All views and tables in the exposed schema and accessible by the active database role for a request are available for querying. They are exposed in one-level deep routes. For instance the full contents of a table people is returned at
GET /people HTTP/1.1
curl "http://localhost:3000/people"
There are no deeply/nested/routes. Each route provides OPTIONS, GET, HEAD, POST, PATCH, and DELETE verbs depending entirely on database permissions.
Note
Why not provide nested routes? Many APIs allow nesting to retrieve related information, such as /films/1/director. We offer a more flexible mechanism (inspired by GraphQL) to embed related information. It can handle one-to-many and many-to-many relationships. This is covered in the section about Resource Embedding.
Horizontal Filtering (Rows)
You can filter result rows by adding conditions on columns. For instance, to return people aged under 13 years old:
GET /people?age=lt.13 HTTP/1.1
curl "http://localhost:3000/people?age=lt.13"
You can evaluate multiple conditions on columns by adding more query string parameters. For instance, to return people who are 18 or older and are students:
GET /people?age=gte.18&student=is.true HTTP/1.1
curl "http://localhost:3000/people?age=gte.18&student=is.true"
Operators
These operators are available:
Abbreviation |
In PostgreSQL |
Meaning |
|---|---|---|
eq |
|
equals |
gt |
|
greater than |
gte |
|
greater than or equal |
lt |
|
less than |
lte |
|
less than or equal |
neq |
|
not equal |
like |
|
LIKE operator (to avoid URL encoding you can use |
ilike |
|
ILIKE operator (to avoid URL encoding you can use |
match |
|
~ operator, see Pattern Matching |
imatch |
|
~* operator, see Pattern Matching |
in |
|
one of a list of values, e.g. |
is |
|
checking for exact equality (null,true,false,unknown) |
fts |
|
Full-Text Search using to_tsquery |
plfts |
|
Full-Text Search using plainto_tsquery |
phfts |
|
Full-Text Search using phraseto_tsquery |
wfts |
|
Full-Text Search using websearch_to_tsquery |
cs |
|
contains e.g. |
cd |
|
contained in e.g. |
ov |
|
overlap (have points in common), e.g. |
sl |
|
strictly left of, e.g. |
sr |
|
strictly right of |
nxr |
|
does not extend to the right of, e.g. |
nxl |
|
does not extend to the left of |
adj |
|
is adjacent to, e.g. |
not |
|
negates another operator, see Logical operators |
or |
|
logical |
and |
|
logical |
For more complicated filters you will have to create a new view in the database, or use a stored procedure. For instance, here’s a view to show “today’s stories” including possibly older pinned stories:
CREATE VIEW fresh_stories AS
SELECT *
FROM stories
WHERE pinned = true
OR published > now() - interval '1 day'
ORDER BY pinned DESC, published DESC;
The view will provide a new endpoint:
GET /fresh_stories HTTP/1.1
curl "http://localhost:3000/fresh_stories"
Logical operators
Multiple conditions on columns are evaluated using AND by default, but you can combine them using OR with the or operator. For example, to return people under 18 or over 21:
GET /people?or=(age.lt.18,age.gt.21) HTTP/1.1
curl "http://localhost:3000/people?or=(age.lt.18,age.gt.21)"
To negate any operator, you can prefix it with not like ?a=not.eq.2 or ?not.and=(a.gte.0,a.lte.100) .
You can also apply complex logic to the conditions:
GET /people?grade=gte.90&student=is.true&or=(age.eq.14,not.and(age.gte.11,age.lte.17)) HTTP/1.1
curl "http://localhost:3000/people?grade=gte.90&student=is.true&or=(age.eq.14,not.and(age.gte.11,age.lte.17))"
Pattern Matching
The pattern-matching operators (like, ilike, match, imatch) exist to support filtering data using patterns instead of concrete strings, as described in the PostgreSQL docs.
To ensure best performance on larger data sets, an appropriate index should be used and even then, it depends on the pattern value and actual data statistics whether an existing index will be used by the query planner or not.
Full-Text Search
The fts filter mentioned above has a number of options to support flexible textual queries, namely the choice of plain vs phrase search and the language used for stemming. Suppose that tsearch is a table with column my_tsv, of type tsvector. The following examples illustrate the possibilities.
GET /tsearch?my_tsv=fts(french).amusant HTTP/1.1
curl "http://localhost:3000/tsearch?my_tsv=fts(french).amusant"
GET /tsearch?my_tsv=plfts.The%20Fat%20Cats HTTP/1.1
curl "http://localhost:3000/tsearch?my_tsv=plfts.The%20Fat%20Cats"
GET /tsearch?my_tsv=not.phfts(english).The%20Fat%20Cats HTTP/1.1
curl "http://localhost:3000/tsearch?my_tsv=not.phfts(english).The%20Fat%20Cats"
GET /tsearch?my_tsv=not.wfts(french).amusant HTTP/1.1
curl "http://localhost:3000/tsearch?my_tsv=not.wfts(french).amusant"
Using websearch_to_tsquery requires PostgreSQL of version at least 11.0 and will raise an error in earlier versions of the database.
Vertical Filtering (Columns)
When certain columns are wide (such as those holding binary data), it is more efficient for the server to withhold them in a response. The client can specify which columns are required using the select parameter.
GET /people?select=first_name,age HTTP/1.1
curl "http://localhost:3000/people?select=first_name,age"
[
{"first_name": "John", "age": 30},
{"first_name": "Jane", "age": 20}
]
The default is *, meaning all columns. This value will become more important below in Resource Embedding.
Renaming Columns
You can rename the columns by prefixing them with an alias followed by the colon : operator.
GET /people?select=fullName:full_name,birthDate:birth_date HTTP/1.1
curl "http://localhost:3000/people?select=fullName:full_name,birthDate:birth_date"
[
{"fullName": "John Doe", "birthDate": "04/25/1988"},
{"fullName": "Jane Doe", "birthDate": "01/12/1998"}
]
Casting Columns
Casting the columns is possible by suffixing them with the double colon :: plus the desired type.
GET /people?select=full_name,salary::text HTTP/1.1
curl "http://localhost:3000/people?select=full_name,salary::text"
[
{"full_name": "John Doe", "salary": "90000.00"},
{"full_name": "Jane Doe", "salary": "120000.00"}
]
JSON Columns
You can specify a path for a json or jsonb column using the arrow operators(-> or ->>) as per the PostgreSQL docs.
CREATE TABLE people (
id int,
json_data json
);
GET /people?select=id,json_data->>blood_type,json_data->phones HTTP/1.1
curl "http://localhost:3000/people?select=id,json_data->>blood_type,json_data->phones"
[
{ "id": 1, "blood_type": "A-", "phones": [{"country_code": "61", "number": "917-929-5745"}] },
{ "id": 2, "blood_type": "O+", "phones": [{"country_code": "43", "number": "512-446-4988"}, {"country_code": "43", "number": "213-891-5979"}] }
]
GET /people?select=id,json_data->phones->0->>number HTTP/1.1
curl "http://localhost:3000/people?select=id,json_data->phones->0->>number"
[
{ "id": 1, "number": "917-929-5745"},
{ "id": 2, "number": "512-446-4988"}
]
This also works with filters:
GET /people?select=id,json_data->blood_type&json_data->>blood_type=eq.A- HTTP/1.1
curl "http://localhost:3000/people?select=id,json_data->blood_type&json_data->>blood_type=eq.A-"
[
{ "id": 1, "blood_type": "A-" },
{ "id": 3, "blood_type": "A-" },
{ "id": 7, "blood_type": "A-" }
]
Note that ->> is used to compare blood_type as text. To compare with an integer value use ->:
GET /people?select=id,json_data->age&json_data->age=gt.20 HTTP/1.1
curl "http://localhost:3000/people?select=id,json_data->age&json_data->age=gt.20"
[
{ "id": 11, "age": 25 },
{ "id": 12, "age": 30 },
{ "id": 15, "age": 35 }
]
Composite / Array Columns
The arrow operators(->, ->>) can also be used for accessing composite fields and array elements.
CREATE TYPE coordinates (
lat decimal(8,6),
long decimal(9,6)
);
CREATE TABLE countries (
id int,
location coordinates,
languages text[]
);
GET /countries?select=id,location->>lat,location->>long,primary_language:languages->0&location->lat=gte.19 HTTP/1.1
curl "http://localhost:3000/countries?select=id,location->>lat,location->>long,primary_language:languages->0&location->lat=gte.19"
[
{
"id": 5,
"lat": "19.741755",
"long": "-155.844437",
"primary_language": "en"
}
]
Important
When using the -> and ->> operators, PostgREST uses a query like to_jsonb(<col>)->'field'. To make filtering and ordering on those nested fields use an index, the index needs to be created on the same expression, including the to_jsonb(...) call:
CREATE INDEX ON mytable ((to_jsonb(data) -> 'identification' ->> 'registration_number'));
Computed / Virtual Columns
Filters may be applied to computed columns(a.k.a. virtual columns) as well as actual table/view columns, even though the computed columns will not appear in the output. For example, to search first and last names at once we can create a computed column that will not appear in the output but can be used in a filter:
CREATE TABLE people (
fname text,
lname text
);
CREATE FUNCTION full_name(people) RETURNS text AS $$
SELECT $1.fname || ' ' || $1.lname;
$$ LANGUAGE SQL;
-- (optional) add an index to speed up anticipated query
CREATE INDEX people_full_name_idx ON people
USING GIN (to_tsvector('english', full_name(people)));
A full-text search on the computed column:
GET /people?full_name=fts.Beckett HTTP/1.1
curl "http://localhost:3000/people?full_name=fts.Beckett"
As mentioned, computed columns do not appear in the output by default. However you can include them by listing them in the vertical filtering select parameter:
GET /people?select=*,full_name HTTP/1.1
curl "http://localhost:3000/people?select=*,full_name"
Important
Computed columns must be created in the exposed schema or in a schema in the extra search path to be used in this way. When placing the computed column in the exposed schema you can use an unnamed argument, as in the example above, to prevent it from being exposed as an RPC under /rpc.
Unicode support
PostgREST supports unicode in schemas, tables, columns and values. To access a table with unicode name, use percent encoding.
To request this:
GET /موارد HTTP/1.1
Do this:
GET /%D9%85%D9%88%D8%A7%D8%B1%D8%AF HTTP/1.1
curl "http://localhost:3000/%D9%85%D9%88%D8%A7%D8%B1%D8%AF"
Table / Columns with spaces
You can request table/columns with spaces in them by percent encoding the spaces with %20:
GET /Order%20Items?Unit%20Price=lt.200 HTTP/1.1
curl "http://localhost:3000/Order%20Items?Unit%20Price=lt.200"
Reserved characters
If filters include PostgREST reserved characters(,, ., :, ()) you’ll have to surround them in percent encoded double quotes %22 for correct processing.
Here Hebdon,John and Williams,Mary are values.
GET /employees?name=in.(%22Hebdon,John%22,%22Williams,Mary%22) HTTP/1.1
curl "http://localhost:3000/employees?name=in.(%22Hebdon,John%22,%22Williams,Mary%22)"
Here information.cpe is a column name.
GET /vulnerabilities?%22information.cpe%22=like.*MS* HTTP/1.1
curl "http://localhost:3000/vulnerabilities?%22information.cpe%22=like.*MS*"
If the value filtered by the in operator has a double quote ("), you can escape it using a backslash "\"". A backslash itself can be used with a double backslash "\\".
Here Quote:" and Backslash:\ are percent-encoded values. Note that %5C is the percent-encoded backslash.
GET /marks?name=in.(%22Quote:%5C%22%22,%22Backslash:%5C%5C%22) HTTP/1.1
curl "http://localhost:3000/marks?name=in.(%22Quote:%5C%22%22,%22Backslash:%5C%5C%22)"
Note
Some HTTP libraries might encode URLs automatically(e.g. axios). In these cases you should use double quotes
"" directly instead of %22.
Ordering
The reserved word order reorders the response rows. It uses a comma-separated list of columns and directions:
GET /people?order=age.desc,height.asc HTTP/1.1
curl "http://localhost:3000/people?order=age.desc,height.asc"
If no direction is specified it defaults to ascending order:
GET /people?order=age HTTP/1.1
curl "http://localhost:3000/people?order=age"
If you care where nulls are sorted, add nullsfirst or nullslast:
GET /people?order=age.nullsfirst HTTP/1.1
curl "http://localhost:3000/people?order=age.nullsfirst"
GET /people?order=age.desc.nullslast HTTP/1.1
curl "http://localhost:3000/people?order=age.desc.nullslast"
You can also use Computed / Virtual Columns to order the results, even though the computed columns will not appear in the output. You can sort by nested fields of JSON Columns with the JSON operators.
Limits and Pagination
PostgREST uses HTTP range headers to describe the size of results. Every response contains the current range and, if requested, the total number of results:
HTTP/1.1 200 OK
Range-Unit: items
Content-Range: 0-14/*
Here items zero through fourteen are returned. This information is available in every response and can help you render pagination controls on the client. This is an RFC7233-compliant solution that keeps the response JSON cleaner.
There are two ways to apply a limit and offset rows: through request headers or query parameters. When using headers you specify the range of rows desired. This request gets the first twenty people.
GET /people HTTP/1.1
Range-Unit: items
Range: 0-19
curl "http://localhost:3000/people" -i \
-H "Range-Unit: items" \
-H "Range: 0-19"
Note that the server may respond with fewer if unable to meet your request:
HTTP/1.1 200 OK
Range-Unit: items
Content-Range: 0-17/*
You may also request open-ended ranges for an offset with no limit, e.g. Range: 10-.
The other way to request a limit or offset is with query parameters. For example
GET /people?limit=15&offset=30 HTTP/1.1
curl "http://localhost:3000/people?limit=15&offset=30"
This method is also useful for embedded resources, which we will cover in another section. The server always responds with range headers even if you use query parameters to limit the query.
Exact Count
In order to obtain the total size of the table or view (such as when rendering the last page link in a pagination control), specify Prefer: count=exact as a request header:
HEAD /bigtable HTTP/1.1
Range-Unit: items
Range: 0-24
Prefer: count=exact
curl "http://localhost:3000/bigtable" -I \
-H "Range-Unit: items" \
-H "Range: 0-24" \
-H "Prefer: count=exact"
Note that the larger the table the slower this query runs in the database. The server will respond with the selected range and total
HTTP/1.1 206 Partial Content
Range-Unit: items
Content-Range: 0-24/3573458
Planned Count
To avoid the shortcomings of exact count, PostgREST can leverage PostgreSQL statistics and get a fairly accurate and fast count.
To do this, specify the Prefer: count=planned header.
HEAD /bigtable?limit=25 HTTP/1.1
Prefer: count=planned
curl "http://localhost:3000/bigtable?limit=25" -I \
-H "Prefer: count=planned"
HTTP/1.1 206 Partial Content
Content-Range: 0-24/3572000
Note that the accuracy of this count depends on how up-to-date are the PostgreSQL statistics tables.
For example in this case, to increase the accuracy of the count you can do ANALYZE bigtable.
See ANALYZE for more details.
Estimated Count
When you are interested in the count, the relative error is important. If you have a planned count of 1000000 and the exact count is 1001000, the error is small enough to be ignored. But with a planned count of 7, an exact count of 28 would be a huge misprediction.
In general, when having smaller row-counts, the estimated count should be as close to the exact count as possible.
To help with these cases, PostgREST can get the exact count up until a threshold and get the planned count when
that threshold is surpassed. To use this behavior, you can specify the Prefer: count=estimated header. The threshold is
defined by db-max-rows.
Here’s an example. Suppose we set db-max-rows=1000 and smalltable has 321 rows, then we’ll get the exact count:
HEAD /smalltable?limit=25 HTTP/1.1
Prefer: count=estimated
curl "http://localhost:3000/smalltable?limit=25" -I \
-H "Prefer: count=estimated"
HTTP/1.1 206 Partial Content
Content-Range: 0-24/321
If we make a similar request on bigtable, which has 3573458 rows, we would get the planned count:
HEAD /bigtable?limit=25 HTTP/1.1
Prefer: count=estimated
curl "http://localhost:3000/bigtable?limit=25" -I \
-H "Prefer: count=estimated"
HTTP/1.1 206 Partial Content
Content-Range: 0-24/3572000
Response Format
PostgREST uses proper HTTP content negotiation (RFC7231) to deliver the desired representation of a resource. That is to say the same API endpoint can respond in different formats like JSON or CSV depending on the client request.
Use the Accept request header to specify the acceptable format (or formats) for the response:
GET /people HTTP/1.1
Accept: application/json
curl "http://localhost:3000/people" \
-H "Accept: application/json"
The current possibilities are:
*/*text/csvapplication/jsonapplication/openapi+jsonapplication/geo+json
and in the special case of a single-column select the following additional three formats; also see the section Response Formats For Scalar Responses:
application/octet-streamtext/plaintext/xml
The server will default to JSON for API endpoints and OpenAPI on the root.
Singular or Plural
By default PostgREST returns all JSON results in an array, even when there is only one item. For example, requesting /items?id=eq.1 returns
[
{ "id": 1 }
]
This can be inconvenient for client code. To return the first result as an object unenclosed by an array, specify vnd.pgrst.object as part of the Accept header
GET /items?id=eq.1 HTTP/1.1
Accept: application/vnd.pgrst.object+json
curl "http://localhost:3000/items?id=eq.1" \
-H "Accept: application/vnd.pgrst.object+json"
This returns
{ "id": 1 }
When a singular response is requested but no entries are found, the server responds with an error message and 406 Not Acceptable status code rather than the usual empty array and 200 status:
{
"message": "JSON object requested, multiple (or no) rows returned",
"details": "Results contain 0 rows, application/vnd.pgrst.object+json requires 1 row",
"hint": null,
"code": "PGRST505"
}
Note
Many APIs distinguish plural and singular resources using a special nested URL convention e.g. /stories vs /stories/1. Why do we use /stories?id=eq.1? The answer is because a singular resource is (for us) a row determined by a primary key, and primary keys can be compound (meaning defined across more than one column). The more familiar nested urls consider only a degenerate case of simple and overwhelmingly numeric primary keys. These so-called artificial keys are often introduced automatically by Object Relational Mapping libraries.
Admittedly PostgREST could detect when there is an equality condition holding on all columns constituting the primary key and automatically convert to singular. However this could lead to a surprising change of format that breaks unwary client code just by filtering on an extra column. Instead we allow manually specifying singular vs plural to decouple that choice from the URL format.
Resource Embedding
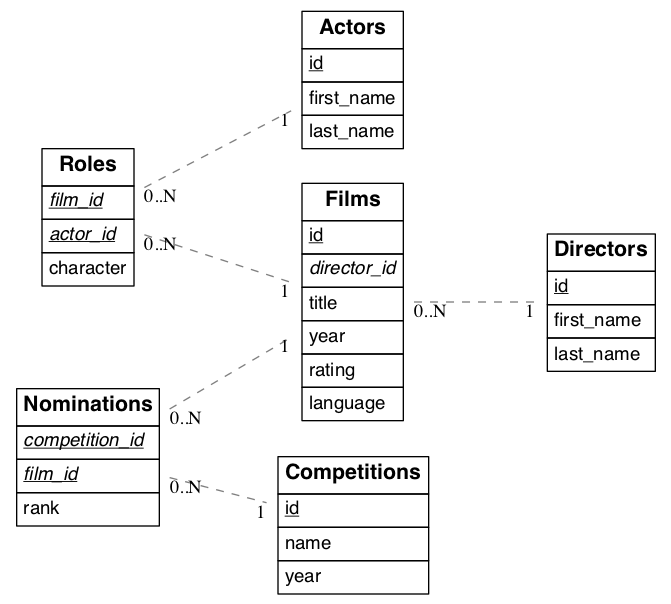
In addition to providing RESTful routes for each table and view, PostgREST allows related resources to be included together in a single API call. This reduces the need for multiple API requests. The server uses foreign keys to determine which tables and views can be returned together. For example, consider a database of films and their awards:
Important
Whenever FOREIGN KEY constraints change in the database schema you must refresh PostgREST’s schema cache for Resource Embedding to work properly. See the section Schema Cache Reloading.
Many-to-one relationships
Since films has a foreign key referencing directors, this establishes a many-to-one relationship between them. Because of this, we’re able
to request all the films and the director for each film.
GET /films?select=title,directors(id,last_name) HTTP/1.1
curl "http://localhost:3000/films?select=title,directors(id,last_name)"
[
{ "title": "Workers Leaving The Lumière Factory In Lyon",
"directors": {
"id": 2,
"last_name": "Lumière"
}
},
{ "title": "The Dickson Experimental Sound Film",
"directors": {
"id": 1,
"last_name": "Dickson"
}
},
{ "title": "The Haunted Castle",
"directors": {
"id": 3,
"last_name": "Méliès"
}
}
]
Note that the embedded directors is returned as a JSON object because of the “to-one” end.
Since the table name is plural, we can be more accurate by making it singular with an alias.
GET /films?select=title,director:directors(id,last_name) HTTP/1.1
curl "http://localhost:3000/films?select=title,director:directors(id,last_name)"
[
{ "title": "Workers Leaving The Lumière Factory In Lyon",
"director": {
"id": 2,
"last_name": "Lumière"
}
},
".."
]
One-to-many relationships
The inverse one-to-many relationship between directors and films is detected based on the foreign key reference. In this case, the embedded films are returned as a JSON array because of the “to-many” end.
GET /directors?select=last_name,films(title) HTTP/1.1
curl "http://localhost:3000/directors?select=last_name,films(title)"
[
{ "last_name": "Lumière",
"films": [
{"title": "Workers Leaving The Lumière Factory In Lyon"}
]
},
{ "last_name": "Dickson",
"films": [
{"title": "The Dickson Experimental Sound Film"}
]
},
{ "last_name": "Méliès",
"films": [
{"title": "The Haunted Castle"}
]
}
]
Many-to-many relationships
Many-to-many relationships are detected based on the join table. The join table must contain foreign keys to other two tables and they must be part of its composite key.
For the many-to-many relationship between films and actors, the join table roles would be:
create table roles(
film_id int references films(id)
, actor_id int references actors(id)
, primary key(film_id, actor_id)
);
-- the join table can also be detected if the composite key has additional columns
create table roles(
id int generated always as identity,
, film_id int references films(id)
, actor_id int references actors(id)
, primary key(id, film_id, actor_id)
);
GET /actors?select=first_name,last_name,films(title) HTTP/1.1
curl "http://localhost:3000/actors?select=first_name,last_name,films(title)"
[
{ "first_name": "Willem",
"last_name": "Dafoe",
"films": [
{"title": "The Lighthouse"}
]
},
".."
]
One-to-one relationships
one-to-one relationships are detected if there’s an unique constraint on a foreign key.
CREATE TABLE technical_specs(
film_id INT REFERENCES films UNIQUE,
runtime TIME,
camera TEXT,
sound TEXT
);
Or if the foreign key is also a primary key.
-- references Films using the primary key as a foreign key
CREATE TABLE technical_specs(
film_id INT PRIMARY KEY REFERENCES films,
runtime TIME,
camera TEXT,
sound TEXT
);
GET /films?select=title,technical_specs(runtime) HTTP/1.1
curl "http://localhost:3000/films?select=title,technical_specs(runtime)"
[
{
"title": "Pulp Fiction",
"technical_specs": {"camera": "Arriflex 35-III"}
},
".."
]
Computed relationships
You can manually define relationships between resources. This is useful for database objects that can’t define foreign keys, like Foreign Data Wrappers. To do this, you can create functions similar to Computed / Virtual Columns.
Assuming there’s a foreign table premieres that we want to relate to films.
create foreign table premieres (
id integer,
location text,
"date" date,
film_id integer
) server import_csv options ( filename '/tmp/directors.csv', format 'csv');
create function film(premieres) returns setof films rows 1 as $$
select * from films where id = $1.film_id
$$ stable language sql;
The above function defines a relationship between premieres (the parameter) and films (the return type) and since there’s a rows 1, this defines a many-to-one relationship.
The name of the function film is arbitrary and can be used to do the embedding:
GET /premieres?select=location,film(name) HTTP/1.1
curl "http://localhost:3000/premieres?select=location,film(name)"
[
{
"location": "Cannes Film Festival",
"film": {"name": "Pulp Fiction"}
},
".."
]
Now let’s define the opposite one-to-many relationship with another function.
create function premieres(films) returns setof premieres as $$
select * from premieres where film_id = $1.id
$$ stable language sql;
Similarly, this function defines a relationship between the parameter films and the return type premieres.
In this case there’s an implicit ROWS 1000 defined by PostgreSQL(search “result_rows” on this PostgreSQL doc),
we consider any value greater than 1 as “many” so this defines a one-to-many relationship.
GET /films?select=name,premieres(name) HTTP/1.1
curl "http://localhost:3000/films?select=name,premieres(name)"
[
{
"name": "Pulp Ficiton",
"premieres": [{"location": "Cannes Festival"}]
},
".."
]
Computed relationships also allow you to override the ones that are automatically detected by PostgREST.
For example, to override the many-to-one relationship between films and directors.
create function directors(films) returns setof directors rows 1 as $$
select * from directors where id = $1.director_id
$$ stable language sql;
Taking advantage of overloaded functions, you can use the same function name for different parameters and thus define relationships from other tables/views to directors.
create function directors(film_schools) returns setof directors as $$
select * from directors where film_school_id = $1.id
$$ stable language sql;
Computed relationships have good performance as their intended design follow the Inlining conditions for table functions.
Warning
Always use
SETOFwhen creating computed relationships. Functions can return a table without usingSETOF, but bear in mind that they will not be inlined.Make sure to correctly label the
to-onepart of the relationship. When using theROWS 1estimation, PostgREST will expect a single row to be returned. If that is not the case, then it will unnest the embedding and return repeated values for the top level resource.
Nested Embedding
If you want to embed through join tables but need more control on the intermediate resources, you can do nested embedding. For instance, you can request the Actors, their Roles and the Films for those Roles:
GET /actors?select=roles(character,films(title,year)) HTTP/1.1
curl "http://localhost:3000/actors?select=roles(character,films(title,year))"
Embedded Filters
Embedded resources can be shaped similarly to their top-level counterparts. To do so, prefix the query parameters with the name of the embedded resource. For instance, to order the actors in each film:
GET /films?select=*,actors(*)&actors.order=last_name,first_name HTTP/1.1
curl "http://localhost:3000/films?select=*,actors(*)&actors.order=last_name,first_name"
This sorts the list of actors in each film but does not change the order of the films themselves. To filter the roles returned with each film:
GET /films?select=*,roles(*)&roles.character=in.(Chico,Harpo,Groucho) HTTP/1.1
curl "http://localhost:3000/films?select=*,roles(*)&roles.character=in.(Chico,Harpo,Groucho)"
Once again, this restricts the roles included to certain characters but does not filter the films in any way. Films without any of those characters would be included along with empty character lists.
An or filter can be used for a similar operation:
GET /films?select=*,roles(*)&roles.or=(character.eq.Gummo,character.eq.Zeppo) HTTP/1.1
curl "http://localhost:3000/films?select=*,roles(*)&roles.or=(character.eq.Gummo,character.eq.Zeppo)"
Limit and offset operations are possible:
GET /films?select=*,actors(*)&actors.limit=10&actors.offset=2 HTTP/1.1
curl "http://localhost:3000/films?select=*,actors(*)&actors.limit=10&actors.offset=2"
Embedded resources can be aliased and filters can be applied on these aliases:
GET /films?select=*,90_comps:competitions(name),91_comps:competitions(name)&90_comps.year=eq.1990&91_comps.year=eq.1991 HTTP/1.1
curl "http://localhost:3000/films?select=*,90_comps:competitions(name),91_comps:competitions(name)&90_comps.year=eq.1990&91_comps.year=eq.1991"
Filters can also be applied on nested embedded resources:
GET /films?select=*,roles(*,actors(*))&roles.actors.order=last_name&roles.actors.first_name=like.*Tom* HTTP/1.1
curl "http://localhost:3000/films?select=*,roles(*,actors(*))&roles.actors.order=last_name&roles.actors.first_name=like.*Tom*"
The result will show the nested actors named Tom and order them by last name. Aliases can also be used instead of the resource names to filter the nested tables.
Embedding with Top-level Filtering
By default, Embedded Filters don’t change the top-level resource(films) rows at all:
GET /films?select=title,actors(first_name,last_name)&actors.first_name=eq.Jehanne HTTP/1.1
curl "http://localhost:3000/films?select=title,actors(first_name,last_name)&actors.first_name=eq.Jehanne
[
{
"title": "Workers Leaving The Lumière Factory In Lyon",
"actors": []
},
{
"title": "The Dickson Experimental Sound Film",
"actors": []
},
{
"title": "The Haunted Castle",
"actors": [
{
"first_name": "Jehanne",
"last_name": "d'Alcy"
}
]
}
]
In order to filter the top level rows you need to add !inner to the embedded resource. For instance, to get only the films that have an actor named Jehanne:
GET /films?select=title,actors!inner(first_name,last_name)&actors.first_name=eq.Jehanne HTTP/1.1
curl "http://localhost:3000/films?select=title,actors!inner(first_name,last_name)&actors.first_name=eq.Jehanne"
[
{
"title": "The Haunted Castle",
"actors": [
{
"first_name": "Jehanne",
"last_name": "d'Alcy"
}
]
}
]
Embedding Partitioned Tables
Embedding can also be done between partitioned tables and other tables.
For example, let’s create the box_office partitioned table that has the gross daily revenue of a film:
CREATE TABLE box_office (
bo_date DATE NOT NULL,
film_id INT REFERENCES test.films NOT NULL,
gross_revenue DECIMAL(12,2) NOT NULL,
PRIMARY KEY (bo_date, film_id)
) PARTITION BY RANGE (bo_date);
-- Let's also create partitions for each month of 2021
CREATE TABLE box_office_2021_01 PARTITION OF test.box_office
FOR VALUES FROM ('2021-01-01') TO ('2021-01-31');
CREATE TABLE box_office_2021_02 PARTITION OF test.box_office
FOR VALUES FROM ('2021-02-01') TO ('2021-02-28');
-- and so until december 2021
Since it contains the films_id foreign key, it is possible to embed box_office and films:
GET /box_office?select=bo_date,gross_revenue,films(title)&gross_revenue=gte.1000000 HTTP/1.1
curl "http://localhost:3000/box_office?select=bo_date,gross_revenue,films(title)&gross_revenue=gte.1000000"
Note
Embedding on partitions is not allowed because it leads to ambiguity errors (see Embedding Disambiguation) between them and their parent partitioned table(more details at #1783(comment)). Custom Queries can be used if this is needed.
Partitioned tables can reference other tables since PostgreSQL 11 but can only be referenced from any other table since PostgreSQL 12.
Embedding Views
PostgREST will infer the relationships of a view based on its source tables. Source tables are the ones referenced in the FROM and JOIN clauses of the view definition. The foreign keys of the relationships must be present in the top SELECT clause of the view for this to work.
For instance, the following view has nominations, films and competitions as source tables:
CREATE VIEW nominations_view AS
SELECT
films.title as film_title
, competitions.name as competition_name
, nominations.rank
, nominations.film_id as nominations_film_id
, films.id as film_id
FROM nominations
JOIN films ON films.id = nominations.film_id
JOIN competitions ON competitions.id = nominations.competition_id;
Since this view contains nominations.film_id, which has a foreign key relationship to films, then we can embed the films table. Similarly, because the view contains films.id, then we can also embed the roles and the actors tables (the last one in a many-to-many relationship):
GET /nominations_view?select=film_title,films(language),roles(character),actors(last_name,first_name)&rank=eq.5 HTTP/1.1
curl "http://localhost:3000/nominations_view?select=film_title,films(language),roles(character),actors(last_name,first_name)&rank=eq.5"
It’s also possible to embed Materialized Views.
Important
It’s not guaranteed that all kinds of views will be embeddable. In particular, views that contain UNIONs will not be made embeddable.
Why? PostgREST detects source table foreign keys in the view by querying and parsing pg_rewrite. This may fail depending on the complexity of the view.
As a workaround, you can use Computed relationships to define manual relationships for views.
If view definitions change you must refresh PostgREST’s schema cache for this to work properly. See the section Schema Cache Reloading.
Embedding Chains of Views
Views can also depend on other views, which in turn depend on the actual source table. For PostgREST to pick up those chains recursively to any depth, all the views must be in the search path, so either in the exposed schema (db-schemas) or in one of the schemas set in db-extra-search-path. This does not apply to the source table, which could be in a private schema as well. See Schema Isolation for more details.
Embedding on Stored Procedures
If you have a Stored Procedure that returns a table type, you can embed its related resources.
Here’s a sample function (notice the RETURNS SETOF films).
CREATE FUNCTION getallfilms() RETURNS SETOF films AS $$
SELECT * FROM films;
$$ LANGUAGE SQL IMMUTABLE;
A request with directors embedded:
GET /rpc/getallfilms?select=title,directors(id,last_name)&title=like.*Workers* HTTP/1.1
curl "http://localhost:3000/rpc/getallfilms?select=title,directors(id,last_name)&title=like.*Workers*"
[
{ "title": "Workers Leaving The Lumière Factory In Lyon",
"directors": {
"id": 2,
"last_name": "Lumière"
}
}
]
Embedding after Insertions/Updates/Deletions
You can embed related resources after doing Insertions, Updates or Deletions.
Say you want to insert a film and then get some of its attributes plus embed its director.
POST /films?select=title,year,director:directors(first_name,last_name) HTTP/1.1
Prefer: return=representation
{
"id": 100,
"director_id": 40,
"title": "127 hours",
"year": 2010,
"rating": 7.6,
"language": "english"
}
curl "http://localhost:3000/films?select=title,year,director:directors(first_name,last_name)" \
-H "Prefer: return=representation" \
-d @- << EOF
{
"id": 100,
"director_id": 40,
"title": "127 hours",
"year": 2010,
"rating": 7.6,
"language": "english"
}
EOF
Response:
{
"title": "127 hours",
"year": 2010,
"director": {
"first_name": "Danny",
"last_name": "Boyle"
}
}
Embedding Disambiguation
For doing resource embedding, PostgREST infers the relationship between two tables based on a foreign key between them. However, in cases where there’s more than one foreign key between two tables, it’s not possible to infer the relationship unambiguously by just specifying the tables names.
Target Disambiguation
For example, suppose you have the following orders and addresses tables:
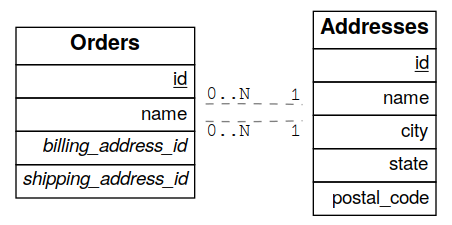
And you try to embed orders with addresses (this is the target):
GET /orders?select=*,addresses(*) HTTP/1.1
curl "http://localhost:3000/orders?select=*,addresses(*)" -i
Since the orders table has two foreign keys to the addresses table — an order has a billing address and a shipping address —
the request is ambiguous and PostgREST will respond with an error:
HTTP/1.1 300 Multiple Choices
{..}
If this happens, you need to disambiguate the request by adding precision to the target. Instead of the table name, you can specify the foreign key constraint name or the column name that is part of the foreign key.
Let’s try first with the foreign key constraint name. To make it clearer we can name it:
ALTER TABLE orders
ADD CONSTRAINT billing_address foreign key (billing_address_id) references addresses(id),
ADD CONSTRAINT shipping_address foreign key (shipping_address_id) references addresses(id);
-- Or if the constraints names were already generated by PostgreSQL we can rename them
-- ALTER TABLE orders
-- RENAME CONSTRAINT orders_billing_address_id_fkey TO billing_address,
-- RENAME CONSTRAINT orders_shipping_address_id_fkey TO shipping_address;
Now we can unambiguously embed the billing address by specifying the billing_address foreign key constraint as the target.
GET /orders?select=name,billing_address(name) HTTP/1.1
curl "http://localhost:3000/orders?select=name,billing_address(name)"
[
{
"name": "Personal Water Filter",
"billing_address": {
"name": "32 Glenlake Dr.Dearborn, MI 48124"
}
}
]
Alternatively, you can specify the column name of the foreign key constraint as the target. This can be aliased to make the result more clear.
GET /orders?select=name,billing_address:billing_address_id(name) HTTP/1.1
curl "http://localhost:3000/orders?select=name,billing_address:billing_address_id(name)"
[
{
"name": "Personal Water Filter",
"billing_address": {
"name": "32 Glenlake Dr.Dearborn, MI 48124"
}
}
]
Hint Disambiguation
If specifying the target is not enough for unambiguous embedding, you can add a hint. For example, let’s assume we create
two views of addresses: central_addresses and eastern_addresses.
PostgREST cannot detect a view as an embedded resource by using a column name or foreign key name as targets, that is why we need to use the view name central_addresses instead. But, still, this is not enough for an unambiguous embed.
GET /orders?select=*,central_addresses(*) HTTP/1.1
curl "http://localhost:3000/orders?select=*,central_addresses(*)" -i
HTTP/1.1 300 Multiple Choices
For solving this case, in addition to the target, we can add a hint.
Here, we still specify central_addresses as the target and use the billing_address foreign key as the hint:
GET /orders?select=*,central_addresses!billing_address(*) HTTP/1.1
curl 'http://localhost:3000/orders?select=*,central_addresses!billing_address(*)' -i
HTTP/1.1 200 OK
[ ... ]
Similarly to the target, the hint can be a table name, foreign key constraint name or column name.
Hints also work alongside !inner if a top level filtering is needed. From the above example:
GET /orders?select=*,central_addresses!billing_address!inner(*)¢ral_addresses.code=AB1000 HTTP/1.1
curl "http://localhost:3000/orders?select=*,central_addresses!billing_address!inner(*)¢ral_addresses.code=AB1000"
Note
If the relationship is so complex that hint disambiguation does not solve it, you can use Computed relationships.
Insertions
All tables and auto-updatable views can be modified through the API, subject to permissions of the requester’s database role.
To create a row in a database table post a JSON object whose keys are the names of the columns you would like to create. Missing properties will be set to default values when applicable.
POST /table_name HTTP/1.1
{ "col1": "value1", "col2": "value2" }
curl "http://localhost:3000/table_name" \
-X POST -H "Content-Type: application/json" \
-d '{ "col1": "value1", "col2": "value2" }'
If the table has a primary key, the response can contain a Location header describing where to find the new object by including the header Prefer: return=headers-only in the request. Make sure that the table is not write-only, otherwise constructing the Location header will cause a permissions error.
On the other end of the spectrum you can get the full created object back in the response to your request by including the header Prefer: return=representation. That way you won’t have to make another HTTP call to discover properties that may have been filled in on the server side. You can also apply the standard Vertical Filtering (Columns) to these results.
URL encoded payloads can be posted with Content-Type: application/x-www-form-urlencoded.
POST /people HTTP/1.1
Content-Type: application/x-www-form-urlencoded
name=John+Doe&age=50&weight=80
curl "http://localhost:3000/people" \
-X POST -H "Content-Type: application/x-www-form-urlencoded" \
-d "name=John+Doe&age=50&weight=80"
Note
When inserting a row you must post a JSON object, not quoted JSON.
Yes
{ "a": 1, "b": 2 }
No
"{ \"a\": 1, \"b\": 2 }"
Some JavaScript libraries will post the data incorrectly if you’re not careful. For best results try one of the Client-Side Libraries built for PostgREST.
Bulk Insert
Bulk insert works exactly like single row insert except that you provide either a JSON array of objects having uniform keys, or lines in CSV format. This not only minimizes the HTTP requests required but uses a single INSERT statement on the back-end for efficiency.
To bulk insert CSV simply post to a table route with Content-Type: text/csv and include the names of the columns as the first row. For instance
POST /people HTTP/1.1
Content-Type: text/csv
name,age,height
J Doe,62,70
Jonas,10,55
curl "http://localhost:3000/people" \
-X POST -H "Content-Type: text/csv" \
--data-binary @- << EOF
name,age,height
J Doe,62,70
Jonas,10,55
EOF
An empty field (,,) is coerced to an empty string and the reserved word NULL is mapped to the SQL null value. Note that there should be no spaces between the column names and commas.
To bulk insert JSON post an array of objects having all-matching keys
POST /people HTTP/1.1
Content-Type: application/json
[
{ "name": "J Doe", "age": 62, "height": 70 },
{ "name": "Janus", "age": 10, "height": 55 }
]
curl "http://localhost:3000/people" \
-X POST -H "Content-Type: application/json" \
-d @- << EOF
[
{ "name": "J Doe", "age": 62, "height": 70 },
{ "name": "Janus", "age": 10, "height": 55 }
]
EOF
Specifying Columns
By using the columns query parameter it’s possible to specify the payload keys that will be inserted and ignore the rest of the payload.
POST /datasets?columns=source,publication_date,figure HTTP/1.1
Content-Type: application/json
{
"source": "Natural Disaster Prevention and Control",
"publication_date": "2015-09-11",
"figure": 1100,
"location": "...",
"comment": "...",
"extra": "...",
"stuff": "..."
}
curl "http://localhost:3000/datasets?columns=source,publication_date,figure" \
-X POST -H "Content-Type: application/json" \
-d @- << EOF
{
"source": "Natural Disaster Prevention and Control",
"publication_date": "2015-09-11",
"figure": 1100,
"location": "...",
"comment": "...",
"extra": "...",
"stuff": "..."
}
EOF
In this case, only source, publication_date and figure will be inserted. The rest of the JSON keys will be ignored.
Using this also has the side-effect of being more efficient for Bulk Insert since PostgREST will not process the JSON and it’ll send it directly to PostgreSQL.
Updates
To update a row or rows in a table, use the PATCH verb. Use Horizontal Filtering (Rows) to specify which record(s) to update. Here is an example query setting the category column to child for all people below a certain age.
PATCH /people?age=lt.13 HTTP/1.1
{ "category": "child" }
curl "http://localhost:3000/people?age=lt.13" \
-X PATCH -H "Content-Type: application/json" \
-d '{ "category": "child" }'
Updates also support Prefer: return=representation plus Vertical Filtering (Columns).
Warning
Beware of accidentally updating every row in a table. To learn to prevent that see Block Full-Table Operations.
Upsert
You can make an upsert with POST and the Prefer: resolution=merge-duplicates header:
POST /employees HTTP/1.1
Prefer: resolution=merge-duplicates
[
{ "id": 1, "name": "Old employee 1", "salary": 30000 },
{ "id": 2, "name": "Old employee 2", "salary": 42000 },
{ "id": 3, "name": "New employee 3", "salary": 50000 }
]
curl "http://localhost:3000/employees" \
-X POST -H "Content-Type: application/json" \
-H "Prefer: resolution=merge-duplicates" \
-d @- << EOF
[
{ "id": 1, "name": "Old employee 1", "salary": 30000 },
{ "id": 2, "name": "Old employee 2", "salary": 42000 },
{ "id": 3, "name": "New employee 3", "salary": 50000 }
]
EOF
By default, upsert operates based on the primary key columns, you must specify all of them. You can also choose to ignore the duplicates with Prefer: resolution=ignore-duplicates. This works best when the primary key is natural, but it’s also possible to use it if the primary key is surrogate (example: “id serial primary key”). For more details read this issue.
Important
After creating a table or changing its primary key, you must refresh PostgREST schema cache for upsert to work properly. To learn how to refresh the cache see Schema Cache Reloading.
On Conflict
By specifying the on_conflict query parameter, you can make upsert work on a column(s) that has a UNIQUE constraint.
POST /employees?on_conflict=name HTTP/1.1
Prefer: resolution=merge-duplicates
[
{ "name": "Old employee 1", "salary": 40000 },
{ "name": "Old employee 2", "salary": 52000 },
{ "name": "New employee 3", "salary": 60000 }
]
curl "http://localhost:3000/employees?on_conflict=name" \
-X POST -H "Content-Type: application/json" \
-H "Prefer: resolution=merge-duplicates" \
-d @- << EOF
[
{ "name": "Old employee 1", "salary": 40000 },
{ "name": "Old employee 2", "salary": 52000 },
{ "name": "New employee 3", "salary": 60000 }
]
EOF
PUT
A single row upsert can be done by using PUT and filtering the primary key columns with eq:
PUT /employees?id=eq.4 HTTP/1.1
{ "id": 4, "name": "Sara B.", "salary": 60000 }
curl "http://localhost/employees?id=eq.4" \
-X PUT -H "Content-Type: application/json" \
-d '{ "id": 4, "name": "Sara B.", "salary": 60000 }'
All the columns must be specified in the request body, including the primary key columns.
Deletions
To delete rows in a table, use the DELETE verb plus Horizontal Filtering (Rows). For instance deleting inactive users:
DELETE /user?active=is.false HTTP/1.1
curl "http://localhost:3000/user?active=is.false" -X DELETE
Deletions also support Prefer: return=representation plus Vertical Filtering (Columns).
DELETE /user?id=eq.1 HTTP/1.1
Prefer: return=representation
curl "http://localhost:3000/user?id=eq.1" -X DELETE \
-H "Prefer: return=representation"
{"id": 1, "email": "johndoe@email.com"}
Warning
Beware of accidentally deleting all rows in a table. To learn to prevent that see Block Full-Table Operations.
Limited Updates/Deletions
You can limit the amount of affected rows by Updates or Deletions with the limit query parameter. For this, you must add an explicit order on a unique column(s).
PATCH /users?limit=10&order=id&last_login=lt.2017-01-01 HTTP/1.1
{ "status": "inactive" }
curl -X PATCH "/users?limit=10&order=id&last_login=lt.2020-01-01" \
-H "Content-Type: application/json" \
-d '{ "status": "inactive" }'
DELETE /users?limit=10&order=id&status=eq.inactive HTTP/1.1
curl -X DELETE "http://localhost:3000/users?limit=10&order=id&status=eq.inactive"
If your table has no unique columns, you can use the ctid system column.
Using offset to target a different subset of rows is also possible.
Note
There is no native UPDATE...LIMIT or DELETE...LIMIT support in PostgreSQL; the generated query simulates that behavior and is based on this Crunchy Data blog post.
Custom Queries
The PostgREST URL grammar limits the kinds of queries clients can perform. It prevents arbitrary, potentially poorly constructed and slow client queries. It’s good for quality of service, but means database administrators must create custom views and stored procedures to provide richer endpoints. The most common causes for custom endpoints are
Table unions
More complicated joins than those provided by Resource Embedding
Geo-spatial queries that require an argument, like “points near (lat,lon)”
Stored Procedures
Every stored procedure in the API-exposed database schema is accessible under the /rpc prefix. The API endpoint supports POST (and in some cases GET) to execute the function.
POST /rpc/function_name HTTP/1.1
curl "http://localhost:3000/rpc/function_name" -X POST
Such functions can perform any operations allowed by PostgreSQL (read data, modify data, and even DDL operations).
To supply arguments in an API call, include a JSON object in the request payload and each key/value of the object will become an argument.
For instance, assume we have created this function in the database.
CREATE FUNCTION add_them(a integer, b integer)
RETURNS integer AS $$
SELECT a + b;
$$ LANGUAGE SQL IMMUTABLE;
Important
Whenever you create or change a function you must refresh PostgREST’s schema cache. See the section Schema Cache Reloading.
The client can call it by posting an object like
POST /rpc/add_them HTTP/1.1
{ "a": 1, "b": 2 }
curl "http://localhost:3000/rpc/add_them" \
-X POST -H "Content-Type: application/json" \
-d '{ "a": 1, "b": 2 }'
3
Procedures must be declared with named parameters. Procedures declared like
CREATE FUNCTION non_named_args(integer, text, integer) ...
cannot be called with PostgREST, since we use named notation internally.
Note that PostgreSQL converts identifier names to lowercase unless you quote them like:
CREATE FUNCTION "someFunc"("someParam" text) ...
PostgreSQL has four procedural languages that are part of the core distribution: PL/pgSQL, PL/Tcl, PL/Perl, and PL/Python. There are many other procedural languages distributed as additional extensions. Also, plain SQL can be used to write functions (as shown in the example above).
Note
Why the /rpc prefix? One reason is to avoid name collisions between views and procedures. It also helps emphasize to API consumers that these functions are not normal restful things. The functions can have arbitrary and surprising behavior, not the standard “post creates a resource” thing that users expect from the other routes.
Immutable and stable functions
PostgREST executes POST requests in a read/write transaction except for functions marked as IMMUTABLE or STABLE. Those must not modify the database and are executed in a read-only transaction compatible for read-replicas.
Procedures that do not modify the database can be called with the HTTP GET verb as well, if desired. PostgREST executes all GET requests in a read-only transaction. Modifying the database inside read-only transactions is not possible and calling volatile functions with GET will fail.
Note
The volatility marker is a promise about the behavior of the function. PostgreSQL will let you mark a function that modifies the database as IMMUTABLE or STABLE without failure. However, because of the read-only transaction this would still fail with PostgREST.
Because add_them is IMMUTABLE, we can alternately call the function with a GET request:
GET /rpc/add_them?a=1&b=2 HTTP/1.1
curl "http://localhost:3000/rpc/add_them?a=1&b=2"
The function parameter names match the JSON object keys in the POST case, for the GET case they match the query parameters ?a=1&b=2.
Calling functions with a single JSON parameter
You can also call a function that takes a single parameter of type JSON by sending the header Prefer: params=single-object with your request. That way the JSON request body will be used as the single argument.
CREATE FUNCTION mult_them(param json) RETURNS int AS $$
SELECT (param->>'x')::int * (param->>'y')::int
$$ LANGUAGE SQL;
POST /rpc/mult_them HTTP/1.1
Prefer: params=single-object
{ "x": 4, "y": 2 }
curl "http://localhost:3000/rpc/mult_them" \
-X POST -H "Content-Type: application/json" \
-H "Prefer: params=single-object" \
-d '{ "x": 4, "y": 2 }'
8
Calling functions with a single unnamed parameter
You can make a POST request to a function with a single unnamed parameter to send raw json/jsonb, bytea, text or xml data.
To send raw JSON, the function must have a single unnamed json or jsonb parameter and the header Content-Type: application/json must be included in the request.
CREATE FUNCTION mult_them(json) RETURNS int AS $$
SELECT ($1->>'x')::int * ($1->>'y')::int
$$ LANGUAGE SQL;
POST /rpc/mult_them HTTP/1.1
Content-Type: application/json
{ "x": 4, "y": 2 }
curl "http://localhost:3000/rpc/mult_them" \
-X POST -H "Content-Type: application/json" \
-d '{ "x": 4, "y": 2 }'
8
Note
If an overloaded function has a single json or jsonb unnamed parameter, PostgREST will call this function as a fallback provided that no other overloaded function is found with the parameters sent in the POST request.
To send raw XML, the parameter type must be xml and the header Content-Type: text/xml must be included in the request.
To send raw binary, the parameter type must be bytea and the header Content-Type: application/octet-stream must be included in the request.
CREATE TABLE files(blob bytea);
CREATE FUNCTION upload_binary(bytea) RETURNS void AS $$
INSERT INTO files(blob) VALUES ($1);
$$ LANGUAGE SQL;
POST /rpc/upload_binary HTTP/1.1
Content-Type: application/octet-stream
file_name.ext
curl "http://localhost:3000/rpc/upload_binary" \
-X POST -H "Content-Type: application/octet-stream" \
--data-binary "@file_name.ext"
HTTP/1.1 200 OK
[ ... ]
To send raw text, the parameter type must be text and the header Content-Type: text/plain must be included in the request.
Calling functions with array parameters
You can call a function that takes an array parameter:
create function plus_one(arr int[]) returns int[] as $$
SELECT array_agg(n + 1) FROM unnest($1) AS n;
$$ language sql;
POST /rpc/plus_one HTTP/1.1
Content-Type: application/json
{"arr": [1,2,3,4]}
curl "http://localhost:3000/rpc/plus_one" \
-X POST -H "Content-Type: application/json" \
-d '{"arr": [1,2,3,4]}'
[2,3,4,5]
For calling the function with GET, you can pass the array as an array literal,
as in {1,2,3,4}. Note that the curly brackets have to be urlencoded({ is %7B and } is %7D).
GET /rpc/plus_one?arr=%7B1,2,3,4%7D' HTTP/1.1
curl "http://localhost:3000/rpc/plus_one?arr=%7B1,2,3,4%7D'"
Note
For versions prior to PostgreSQL 10, to pass a PostgreSQL native array on a POST payload, you need to quote it and use an array literal:
POST /rpc/plus_one HTTP/1.1
{ "arr": "{1,2,3,4}" }
curl "http://localhost:3000/rpc/plus_one" \
-X POST -H "Content-Type: application/json" \
-d '{ "arr": "{1,2,3,4}" }'
In these versions we recommend using function parameters of type JSON to accept arrays from the client.
Calling variadic functions
You can call a variadic function by passing a JSON array in a POST request:
create function plus_one(variadic v int[]) returns int[] as $$
SELECT array_agg(n + 1) FROM unnest($1) AS n;
$$ language sql;
POST /rpc/plus_one HTTP/1.1
Content-Type: application/json
{"v": [1,2,3,4]}
curl "http://localhost:3000/rpc/plus_one" \
-X POST -H "Content-Type: application/json" \
-d '{"v": [1,2,3,4]}'
[2,3,4,5]
In a GET request, you can repeat the same parameter name:
GET /rpc/plus_one?v=1&v=2&v=3&v=4 HTTP/1.1
curl "http://localhost:3000/rpc/plus_one?v=1&v=2&v=3&v=4"
Repeating also works in POST requests with Content-Type: application/x-www-form-urlencoded:
POST /rpc/plus_one HTTP/1.1
Content-Type: application/x-www-form-urlencoded
v=1&v=2&v=3&v=4
curl "http://localhost:3000/rpc/plus_one" \
-X POST -H "Content-Type: application/x-www-form-urlencoded" \
-d 'v=1&v=2&v=3&v=4'
Scalar functions
PostgREST will detect if the function is scalar or table-valued and will shape the response format accordingly:
GET /rpc/add_them?a=1&b=2 HTTP/1.1
curl "http://localhost:3000/rpc/add_them?a=1&b=2"
3
GET /rpc/best_films_2017 HTTP/1.1
curl "http://localhost:3000/rpc/best_films_2017"
[
{ "title": "Okja", "rating": 7.4},
{ "title": "Call me by your name", "rating": 8},
{ "title": "Blade Runner 2049", "rating": 8.1}
]
To manually choose a return format such as binary, plain text or XML, see the section Response Formats For Scalar Responses.
Bulk Call
It’s possible to call a function in a bulk way, analogously to Bulk Insert. To do this, you need to add the
Prefer: params=multiple-objects header to your request.
POST /rpc/add_them HTTP/1.1
Content-Type: text/csv
Prefer: params=multiple-objects
a,b
1,2
3,4
curl "http://localhost:3000/rpc/add_them" \
-X POST -H "Content-Type: text/csv" \
-H "Prefer: params=multiple-objects" \
--data-binary @- << EOF
a,b
1,2
3,4
EOF
[ 3, 7 ]
If you have large payloads to process, it’s preferable you instead use a function with an array parameter or JSON parameter, as this will be more efficient.
It’s also possible to Specify Columns on functions calls.
Function filters
A function that returns a table type response can be shaped using the same filters as the ones used for tables and views:
CREATE FUNCTION best_films_2017() RETURNS SETOF films ..
GET /rpc/best_films_2017?select=title,director:directors(*) HTTP/1.1
curl "http://localhost:3000/rpc/best_films_2017?select=title,director:directors(*)"
GET /rpc/best_films_2017?rating=gt.8&order=title.desc HTTP/1.1
curl "http://localhost:3000/rpc/best_films_2017?rating=gt.8&order=title.desc"
Overloaded functions
You can call overloaded functions with different number of arguments.
CREATE FUNCTION rental_duration(customer_id integer) ..
CREATE FUNCTION rental_duration(customer_id integer, from_date date) ..
GET /rpc/rental_duration?customer_id=232 HTTP/1.1
curl "http://localhost:3000/rpc/rental_duration?customer_id=232"
GET /rpc/rental_duration?customer_id=232&from_date=2018-07-01 HTTP/1.1
curl "http://localhost:3000/rpc/rental_duration?customer_id=232&from_date=2018-07-01"
Important
Overloaded functions with the same argument names but different types are not supported.
Response Formats For Scalar Responses
For scalar return values such as
single-column selects on tables or
scalar functions,
you can set the additional content types
application/octet-streamtext/plaintext/xml
as part of the Accept header.
Example 1: If you want to return raw binary data from a bytea column, you must specify application/octet-stream as part of the Accept header
and select a single column ?select=bin_data.
GET /items?select=bin_data&id=eq.1 HTTP/1.1
Accept: application/octet-stream
curl "http://localhost:3000/items?select=bin_data&id=eq.1" \
-H "Accept: application/octet-stream"
Example 2: You can request XML output when calling Stored Procedures that return a scalar value of type text/xml. You are not forced to use select for this case.
CREATE FUNCTION generate_xml_content(..) RETURNS xml ..
POST /rpc/generate_xml_content HTTP/1.1
Accept: text/xml
curl "http://localhost:3000/rpc/generate_xml_content" \
-X POST -H "Accept: text/xml"
Example 3: If the stored procedure returns non-scalar values, you need to do a select in the same way as for GET binary output.
CREATE FUNCTION get_descriptions(..) RETURNS SETOF TABLE(id int, description text) ..
POST /rpc/get_descriptions?select=description HTTP/1.1
Accept: text/plain
curl "http://localhost:3000/rpc/get_descriptions?select=description" \
-X POST -H "Accept: text/plain"
Note
If more than one row would be returned the binary/plain-text/xml results will be concatenated with no delimiter.
OpenAPI Support
Every API hosted by PostgREST automatically serves a full OpenAPI description on the root path. This provides a list of all endpoints (tables, foreign tables, views, functions), along with supported HTTP verbs and example payloads.
Note
By default, this output depends on the permissions of the role that is contained in the JWT role claim (or the db-anon-role if no JWT is sent). If you need to show all the endpoints disregarding the role’s permissions, set the openapi-mode config to ignore-privileges.
For extra customization, the OpenAPI output contains a “description” field for every SQL comment on any database object. For instance,
COMMENT ON SCHEMA mammals IS
'A warm-blooded vertebrate animal of a class that is distinguished by the secretion of milk by females for the nourishment of the young';
COMMENT ON TABLE monotremes IS
'Freakish mammals lay the best eggs for breakfast';
COMMENT ON COLUMN monotremes.has_venomous_claw IS
'Sometimes breakfast is not worth it';
These unsavory comments will appear in the generated JSON as the fields, info.description, definitions.monotremes.description and definitions.monotremes.properties.has_venomous_claw.description.
Also if you wish to generate a summary field you can do it by having a multiple line comment, the summary will be the first line and the description the lines that follow it:
COMMENT ON TABLE entities IS
$$Entities summary
Entities description that
spans
multiple lines$$;
If you need to include the security and securityDefinitions options, set the openapi-security-active configuration to true.
You can use a tool like Swagger UI to create beautiful documentation from the description and to host an interactive web-based dashboard. The dashboard allows developers to make requests against a live PostgREST server, and provides guidance with request headers and example request bodies.
Important
The OpenAPI information can go out of date as the schema changes under a running server. To learn how to refresh the cache see Schema Cache Reloading.
OPTIONS
You can verify which HTTP methods are allowed on endpoints for tables and views by using an OPTIONS request. These methods are allowed depending on what operations can be done on the table or view, not on the database permissions assigned to them.
For a table named people, OPTIONS would show:
OPTIONS /people HTTP/1.1
curl "http://localhost:3000/people" -X OPTIONS -i
HTTP/1.1 200 OK
Allow: OPTIONS,GET,HEAD,POST,PUT,PATCH,DELETE
For a view, the methods are determined by the presence of INSTEAD OF TRIGGERS.
Method allowed |
View’s requirements |
|---|---|
OPTIONS, GET, HEAD |
None (Always allowed) |
POST |
INSTEAD OF INSERT TRIGGER |
PUT |
INSTEAD OF INSERT TRIGGER, INSTEAD OF UPDATE TRIGGER, also requires the presence of a primary key |
PATCH |
INSTEAD OF UPDATE TRIGGER |
DELETE |
INSTEAD OF DELETE TRIGGER |
All the above methods are allowed for auto-updatable views |
|
For functions, the methods depend on their volatility. VOLATILE functions allow only OPTIONS,POST, whereas the rest also permit GET,HEAD.
Important
Whenever you add or remove tables or views, or modify a view’s INSTEAD OF TRIGGERS on the database, you must refresh PostgREST’s schema cache for OPTIONS requests to work properly. See the section Schema Cache Reloading.
CORS
PostgREST sets highly permissive cross origin resource sharing, that is why it accepts Ajax requests from any domain.
It also handles preflight requests done by the browser, which are cached using the returned Access-Control-Max-Age: 86400 header (86400 seconds = 24 hours). This is useful to reduce the latency of the subsequent requests.
A POST preflight request would look like this:
OPTIONS /items HTTP/1.1
Origin: http://example.com
Access-Control-Allow-Method: POST
Access-Control-Allow-Headers: Content-Type
curl -i "http://localhost:3000/items" \
-X OPTIONS \
-H "Origin: http://example.com" \
-H "Access-Control-Request-Method: POST" \
-H "Access-Control-Request-Headers: Content-Type"
HTTP/1.1 200 OK
Access-Control-Allow-Origin: http://example.com
Access-Control-Allow-Credentials: true
Access-Control-Allow-Methods: GET, POST, PATCH, PUT, DELETE, OPTIONS, HEAD
Access-Control-Allow-Headers: Authorization, Content-Type, Accept, Accept-Language, Content-Language
Access-Control-Max-Age: 86400
Switching Schemas
You can switch schemas at runtime with the Accept-Profile and Content-Profile headers. You can only switch to a schema that is included in db-schemas.
For GET or HEAD, the schema to be used can be selected through the Accept-Profile header:
GET /items HTTP/1.1
Accept-Profile: tenant2
curl "http://localhost:3000/items" \
-H "Accept-Profile: tenant2"
For POST, PATCH, PUT and DELETE, you can use the Content-Profile header for selecting the schema:
POST /items HTTP/1.1
Content-Profile: tenant2
{...}
curl "http://localhost:3000/items" \
-X POST -H "Content-Type: application/json" \
-H "Content-Profile: tenant2" \
-d '{...}'
You can also select the schema for Stored Procedures and OpenAPI Support.
Note
These headers are based on the nascent “Content Negotiation by Profile” spec: https://www.w3.org/TR/dx-prof-conneg
HTTP Context
Accessing Request Path and Method
You can also access the request path and method with request.path and request.method.
-- You can get the path of the request with
SELECT current_setting('request.path', true);
-- You can get the method of the request with
SELECT current_setting('request.method', true);
Setting Response Headers
PostgREST reads the response.headers SQL variable to add extra headers to the HTTP response. Stored procedures can modify this variable. For instance, this statement would add caching headers to the response:
-- tell client to cache response for two days
SELECT set_config('response.headers',
'[{"Cache-Control": "public"}, {"Cache-Control": "max-age=259200"}]', true);
Notice that the variable should be set to an array of single-key objects rather than a single multiple-key object. This is because headers such as Cache-Control or Set-Cookie need to be repeated when setting multiple values and an object would not allow the repeated key.
Note
PostgREST provided headers such as Content-Type, Location, etc. can be overriden this way. Note that irrespective of overridden Content-Type response header, the content will still be converted to JSON, unless you also set raw-media-types to something like text/html.
Setting headers via pre-request
By using a db-pre-request function, you can add headers to GET/POST/PATCH/PUT/DELETE responses. As an example, let’s add some cache headers for all requests that come from an Internet Explorer(6 or 7) browser.
create or replace function custom_headers() returns void as $$
declare
user_agent text := current_setting('request.headers', true)::json->>'user-agent';
begin
if user_agent similar to '%MSIE (6.0|7.0)%' then
perform set_config('response.headers',
'[{"Cache-Control": "no-cache, no-store, must-revalidate"}]', false);
end if;
end; $$ language plpgsql;
-- set this function on postgrest.conf
-- db-pre-request = custom_headers
Now when you make a GET request to a table or view, you’ll get the cache headers.
GET /people HTTP/1.1
User-Agent: Mozilla/4.01 (compatible; MSIE 6.0; Windows NT 5.1)
curl "http://localhost:3000/people" -i \
-H "User-Agent: Mozilla/4.01 (compatible; MSIE 6.0; Windows NT 5.1)"
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Cache-Control: no-cache, no-store, must-revalidate
Setting Response Status Code
You can set the response.status GUC to override the default status code PostgREST provides. For instance, the following function would replace the default 200 status code.
create or replace function teapot() returns json as $$
begin
perform set_config('response.status', '418', true);
return json_build_object('message', 'The requested entity body is short and stout.',
'hint', 'Tip it over and pour it out.');
end;
$$ language plpgsql;
GET /rpc/teapot HTTP/1.1
curl "http://localhost:3000/rpc/teapot" -i
HTTP/1.1 418 I'm a teapot
{
"message" : "The requested entity body is short and stout.",
"hint" : "Tip it over and pour it out."
}
If the status code is standard, PostgREST will complete the status message(I’m a teapot in this example).
Raise errors with HTTP Status Codes
Stored procedures can return non-200 HTTP status codes by raising SQL exceptions. For instance, here’s a saucy function that always responds with an error:
CREATE OR REPLACE FUNCTION just_fail() RETURNS void
LANGUAGE plpgsql
AS $$
BEGIN
RAISE EXCEPTION 'I refuse!'
USING DETAIL = 'Pretty simple',
HINT = 'There is nothing you can do.';
END
$$;
Calling the function returns HTTP 400 with the body
{
"message":"I refuse!",
"details":"Pretty simple",
"hint":"There is nothing you can do.",
"code":"P0001"
}
Note
Keep in mind that RAISE EXCEPTION will abort the transaction and rollback all changes. If you don’t want this, you can instead use the response.status GUC.
One way to customize the HTTP status code is by raising particular exceptions according to the PostgREST error to status code mapping. For example, RAISE insufficient_privilege will respond with HTTP 401/403 as appropriate.
For even greater control of the HTTP status code, raise an exception of the PTxyz type. For instance to respond with HTTP 402, raise ‘PT402’:
RAISE sqlstate 'PT402' using
message = 'Payment Required',
detail = 'Quota exceeded',
hint = 'Upgrade your plan';
Returns:
HTTP/1.1 402 Payment Required
Content-Type: application/json; charset=utf-8
{
"message": "Payment Required",
"details": "Quota exceeded",
"hint": "Upgrade your plan",
"code": "PT402"
}
Execution plan
You can get the EXPLAIN execution plan of a request by adding the Accept: application/vnd.pgrst.plan header when db-plan-enabled is set to true.
GET /users?select=name&order=id HTTP/1.1
Accept: application/vnd.pgrst.plan
curl "http://localhost:3000/users?select=name&order=id" \
-H "Accept: application/vnd.pgrst.plan"
Aggregate (cost=73.65..73.68 rows=1 width=112)
-> Index Scan using users_pkey on users (cost=0.15..60.90 rows=850 width=36)
The output of the plan is generated in text format by default but you can change it to JSON by using the +json suffix.
GET /users?select=name&order=id HTTP/1.1
Accept: application/vnd.pgrst.plan+json
curl "http://localhost:3000/users?select=name&order=id" \
-H "Accept: application/vnd.pgrst.plan+json"
[
{
"Plan": {
"Node Type": "Aggregate",
"Strategy": "Plain",
"Partial Mode": "Simple",
"Parallel Aware": false,
"Async Capable": false,
"Startup Cost": 73.65,
"Total Cost": 73.68,
"Plan Rows": 1,
"Plan Width": 112,
"Plans": [
{
"Node Type": "Index Scan",
"Parent Relationship": "Outer",
"Parallel Aware": false,
"Async Capable": false,
"Scan Direction": "Forward",
"Index Name": "users_pkey",
"Relation Name": "users",
"Alias": "users",
"Startup Cost": 0.15,
"Total Cost": 60.90,
"Plan Rows": 850,
"Plan Width": 36
}
]
}
}
]
By default the plan is assumed to generate the JSON representation of a resource(application/json), but you can obtain the plan for the different representations that PostgREST supports by adding them to the for parameter. For instance, to obtain the plan for a text/xml, you would use Accept: application/vnd.pgrst.plan; for="text/xml.
The other available parameters are analyze, verbose, settings, buffers and wal, which correspond to the EXPLAIN command options. To use the analyze and wal parameters for example, you would add them like Accept: application/vnd.pgrst.plan; options=analyze|wal.
Note that akin to the EXPLAIN command, the changes will be committed when using the analyze option. To avoid this, you can use the db-tx-end and the Prefer: tx=rollback header.